In our exploration of Power Query’s types, number is next!
You might think that working with numbers would be so simple we’d hardly need to talk about them. However, there’s a got-ya that can bite: if you’re not careful, you can end up with arithmetic not producing the results you expect! After we go over M’s syntax for numeric literals, we’ll talk about this potential pain-point and how to not let it cause unexpected complications.
Also, in M, columns can be tagged to identify the specific kind of numbers they contain. Properly setting this subtype can improve performance and storage as well as enhance the default formatting used for the column’s values. We’ll learn how to do this (it’s easy!).
Series Index
- Introduction, Simple Expressions &
let(part 1) - Functions: Defining (part 2)
- Functions: Function Values, Passing, Returning, Defining Inline, Recursion (part 3)
- Variables & Identifiers (part 4)
- Paradigm (part 5)
- Types—Intro & Text (Strings) (part 6)
- Types—Numbers (part 7) [this post]
- Types—The Temporal Family (part 8)
- Types—Logical, Null, Binary (part 9)
- Types—List, Record (part 10)
- Tables—Syntax (part 11)
- Tables—Table Think I (part 12)
- Tables—Table Think II (part 13)
- Control Structure (part 14)
- Error Handling (part 15)
- Type System I – Basics (part 16)
- Type System II – Facets (part 17)
- Type System III – Custom Types (part 18)
- Type System IV – Ascription, Conformance and Equality’s “Strange” Behaviors (part 19)
- Metadata (part 20)
- Identifier Scope & Sections (part 21)
- Identifier Scope II – Controlling the Global Environment, Closures (part 22)
- Query Folding I (part 23)
- Query Folding II (part 24)
- Extending the Global Environment (part 25)
- More to come!
Numbers
Literal Syntax
Literal numbers can be typed out as whole numbers:
0
5
-7
Decimals:
2.5
0.5
.5
In exponential form:
1.2e10
1.2e-5
1.2E-5
…and using hexadecimal syntax:
0xFF
0xff
0XFF
0Xff
Above, notice how both the exponent indicator (the “e”) and the characters used in the hexadecimals are case-insensitive. Upper- and lower-case are allowed and behave identically.
In the case of numbers with decimal points, no digits are required before the decimal point but at least one is required after it.
.5 // valid - no digit before the decimal
.2e25 // valid - no digit before the decimal
5. // invalid - must have at least one digit after the decimal
2.e25 // invalid - must have at least one digit after the decimal
Special Numbers
In addition to ordinary numbers, the special “numbers” infinity and not-a-number are supported.
#infinity // produced by an expression like 1/0
#nan // produced by an expression like 0/0
Negation
Numbers can be negated using the unary minus operator—a fancy way of saying that a number can be changed to its negative by proceeding it with a minus sign.
-5
-5e-2
-#infinity // produced by an expression like -1/0
(Note: Syntax-wise, it’s permissible to write -#nan. However, this won’t negate not-a-number; instead, the ‘-’ will quietly be ignored. This makes sense, as not-a-number is a sign-less concept.)
Just a Style
The various styles used to type out numbers are just that: styles. The different options are offered as a convenience to the mashup author. Each style’s syntax creates an expression that produces a numeric value. If two expressions evaluate to the same number, their values are equal—even if the expressions are written using different syntax styles.
0x0A = 10 // true as both literals evaluate to 10
How accurate is accurate enough? (Precision)
With numeric literal syntax out of the way, we come to the potential ouch point when working with numbers in M:
Both the arithmetic (+, -, *, /) and equality (=) operators always use double precision. Double precision sacrifices some accuracy for the sake of efficiency. Decimal precision—potentially slower but producing more accurate results—is available but must be explicitly requested, when desired.
“Wait a minute!,” you might say. “I thought computes don’t lie. This just doesn’t make sense. Are you saying that two numbers added together might not always equal the sum of those two numbers?!”
Let’s take a look:
What should 0.1 + 0.2 equal? 0.3, correct?! What about a very large number plus 1—shouldn’t it equal that very large number plus 1?! Well, both are not necessarily so with double precision:
0.1 + 0.2 // 0.30000000000000004
10000000000000000 + 1 // 10000000000000000
In contrast, decimal precision produces the expected, exactly accurate totals.
Value.Add(10000000000000000, 1, Precision.Decimal) // 10000000000000001
Above, the library method Value.Add was used to force the addition to occur using decimal precision. There are also Value methods for subtraction, multiplication and division. Each allows decimal precision to be specified.
The difference between the two precisions can also show up when doing comparisons. Notice how the second expression in each pair uses Value.Compare to specify the use of decimal precision.
0.10000000000000001 = 0.1 // equal — comparison done using double precision
Value.Compare(0.10000000000000001 , 0.1, Precision.Decimal) // not equal
10000000000000000 = 10000000000000001 // equal — comparison done using double precision
Value.Compare(10000000000000000 , 10000000000000001, Precision.Decimal) // not equal
What’s Going On?!
Let’s take a step back and broaden our scope of discussion for a moment. Let’s talk about what precision is, as far as computers and numbers go, and then why computers offer choices about precision instead of only and always using the most accurate precision possible.
Remember back in grade school, you learned that 1/3 can’t be precisely represented as a finite decimal. It’s 0.33333333…, with the threes repeating forever and ever. Since we can’t write an infinite number of threes, if we’re going to work with 1/3 in decimal form we have to pick a level of accuracy that’s good enough for the situation at hand. For example, if an item is priced as 3 for a dollar, we could represent its price in decimal form as $0.33.
Did you notice the precision loss? Each item costs 1/3 dollar. However, if you multiply $0.33 times 3, the result isn’t $1. Instead, it’s $0.99. A loss of $0.01 occurred. This loss could have been avoided if we worked with the price in its fractional form (1/3 dollar * 3 = exactly $1). However, it’s often more convenient to work with monetary amounts in decimal form—it’s often so much more convenient that we’re okay with tolerating a small loss in accuracy so that we can do it.
Notice that the loss of accuracy wasn’t because we were careless in how we did arithmetic. Instead, the inaccuracy stemmed from the fact that the number system we used (decimal) couldn’t precisely represent the fractional value 1/3. To work around this limitation, an approximation was used (0.33). While all the math done on the approximation was 100% correct and the result was 100% predicable, the result was not 100% accurate because it was based on an approximation.
It’s much the same with computers. To make a long story short, in a nutshell, similar to how we can use fractions or decimals to represent numbers, computers also have multiple ways to handle numbers. Our choice between decimals and fractions involved deciding between more convenient to work with and exactly accurate. With computers, the options are different, because computers think differently than the human brain, but the same trade-off applies: convenience vs. accuracy Since Power Query mashups are executed by computers, the same choice applies to working with numbers in M.
Specifically, in M, double precision (conforms to IEEE Standard for Floating-Point Arithmetic [IEEE 754-2008]) is more convenient for the computer to work with, offering the potential for better computational performance and more efficient storage. Decimal precision is more accurate.
(For reference: Microsoft Excel does all its math at double precision, with an extra limit imposed on the number of significant digits. If you are an Excel user, you’ve already been living in, and likely operating successfully in, a world with double precision ramifications, whether or not you’ve realized it.)
Which to Choose?
Perhaps it would help to think of it this way: If you’re comparing the distance between various stars, does being exactly accurate to the smallest nuance matter? Likely not because that level of accuracy is probably irrelevant considering the scale of the numbers you’re working with (trillions of miles). Given the context, losing a little preciseness to gain improved efficiency is probably a reasonable choice. On the other hand, you probably don’t want your bank sacrificing a little accuracy for improved efficiency when they calculate the balance of your bank account. In this context, accuracy is paramount, regardless of the efficiency cost.
In M, this accuracy is achieved by using Value functions to mandate decimal precision (as several examples above demonstrate). The necessity of using Value functions to achieve decimal precision applies even when the numbers at hand are already stored as decimals or as non-floating point numbers. The standard arithmetic and comparison operators convert their inputs to double precision, regardless the source arguments’ storage precision. If you want decimal precision for operations, the only way to get it is to specify it!
The Third Alternative
There is a compromise option. If you’d like the benefits of double precision but with increased accuracy, you can sometimes achieve this using rounding. If the problem we’re trying to avoid is slightly inaccurate numbers after the decimal point and we know that there is only a fixed number of decimal places we care about, we might be able to round away the extraneous decimal places and convert the close-to-accurate result into exactly what we expect.
Back to the example of adding 0.1 + 0.2: Let’s pretend these values represent dollar amounts where only at most the first two digits after the decimal point matter. By rounding away the irrelevant digits, we can convert the long ugly result of the double precision computation into the 100% accurate result we expected.
0.1 + 0.2 // 0.30000000000000004
Number.Round(0.1 + 0.2, 2) // 0.3 — equivalent to 0.30
Ah, but rounding isn’t always the wonder solution.
Let’s jump back to the example of representing 1/3 as a decimal. What if we convert this fraction to $0.333 instead of $0.33? Multiplying $0.333 produces $0.999 which rounded to two digits is $1—the exactly accurate total we were looking for.
Nice…but now try this: Multiply 10 items times the $0.333 price. The total is $3.33. Add ten more, then yet 10 more. The sum is $9.99 ($3.33 + $3.33 + $3.33). However, that sum represents 30 items at 1/3 dollar each, which should equal a total of exactly $10. Ouch! Rounding didn’t help us here.
Rounding is an option to keep in your back pocket for when it’s helpful—but be careful that you don’t treat it as a “one size fits all, solves all problems with double precision math” solution. Using it can be excellent—if you understand exactly how it will behave in your context. Otherwise, using it can bite!
Specifying Specific Subtype Claims
When working with a table in Power Query’s UI, you may have noticed that there’s a Change Type option for each column.
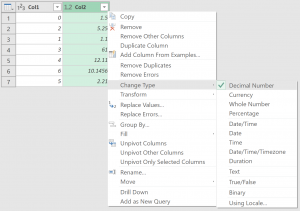
Four options are presented for numbers:
- Decimal Number (think: floating-point decimal number)
- Currency (think: fixed precision number allowing 4 digits after the decimal place)
- Whole Number (think: integer—numbers with no decimal point allowed)
- Percentage (think: number where 0 indicates 0%; 1.0 = 100%, -1.0 = -100%, 2.5 = 2.5 = 250%, etc.)
Decimal Number corresponds with M’s base number type; the others are subtype claims (or facets) of type number. Choosing one of this dropdown’s options tags the column as containing values of the specific type or pseudo-subtype and converts the data in that column to align with the chosen type or the chosen subtype claim.
For example, if you specify that a column is Whole Number, the column will be tagged as containing whole numbers and any numbers in that column with decimal components will be rounded (e.g. 1.75 becomes 2).
However, the values in the column will still be of type number; “whole number” (technically, Int64) is just a claim, not a true data type from the mashup engine’s perspective.
This type/pseudo-subtype tagging can have (significant) benefits outside of Power Query. When the data output by your mashup is handed to the tool hosting Power Query (e.g. Microsoft Excel, Microsoft Power BI or Microsoft SSIS), that tool can use this type information to better handle the values in the column, potentially leading to more efficient storage and calculations as well as improved styling of the column’s values. In the case of the latter, the host environment might prefix a dollar sign (or other culturally-appropriate currency indicator) to numbers from a column tagged as currency.
Best Practice Recommendation: Ensure that table columns containing numbers have their type set to the most specific applicable number type or subtype claim.
Conclusion
Whew! Covering numeric literals was the easy part! The discussion on precision was long but important. Hopefully, you’ve come away with enough knowledge to be able to make conscious decisions related to it. Better to make a conscious decision than go along ignorantly in bliss until you’re bitten. Oh, and don’t forget to strongly consider ensuring that all table columns containing numbers have their type set to the most appropriate choice.
With numbers out of the way, next time we’ll keep working through the primitive types, specifically the temporal types (date, time, datetime, datetimezone and duration).
Until then, happy coding!
Revision History
- 2022-07-05: Incremental improvement to the description of subtype claims; added a note about Excel using double precision.
This is the first time, I do understand how P.Q. is working, how queries been working, built up.
Especially costume function, and let in structure, now I understand what is going on inside M engine.
Thank you Ben you are hero.
Thank you for your kind words!
Appreciate knowing this! I frequently the
List.Sum()function when grouping data or adding across columns. Reading your post made me wonder what kind of precisionList.Sum()uses, since I frequently find myself nesting it insideNumber.Round()after the fact. Turns out thatList.Sum()lets you DEFINE the precision via an optional argument! So good. Like you said, speed may dictate using one or the other, but it is really good to know this is an option.= List.Sum({0.1, 0.2}) // 0.30000000000000004= List.Sum({0.1, 0.2}, Precision.Decimal) // 0.3
The issue with “0.1 + 0.2” is common to most programming languages and not just M. There’s even a website that lists the results in various languages: https://0.30000000000000004.com/
BTW, I’m really enjoying this series of articles!
Thanks for your kind words! Yes, you are correct—this “issue” is not unique to Power Query but rather to floating point numbers.