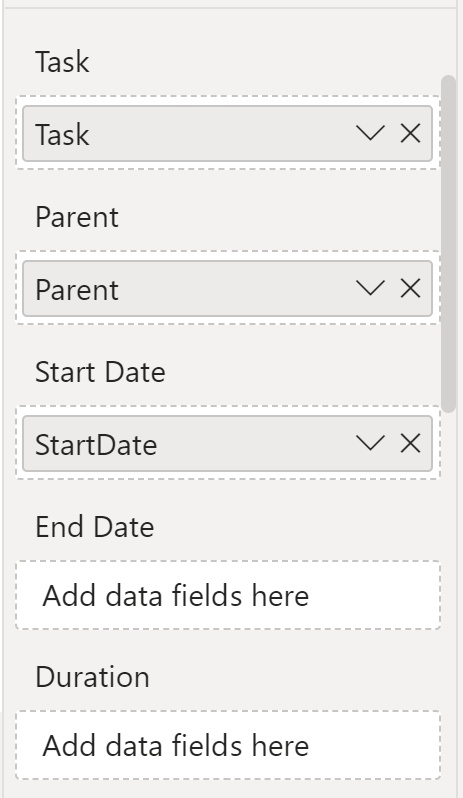
On a project recently, I wanted to use Microsoft’s Gantt chart visual for Microsoft Power BI. Try as I might, I couldn’t get the visual to accept an end date or duration. I could drag a column from the data model over to the field box for End Date or Duration but the field would not “drop” into the field box. Instead, when I’d let go of the mouse button, the box would stay empty.
I built a small test Power BI report + dataset from scratch, and the Gantt chart visual worked fine—no problems with configuring it by dragging and dropping fields.
Why wouldn’t this Gantt visual work with my existing Power BI report, but work just fine with the test report?
Uh oh! You’re using Microsoft Power BI or Excel and you’ve discovered that Power Query does not have a built-in connector for the data source you’re interested in consuming.
Question: What does this mean for you?
Answer: (pick which of the below you think is most likely correct)
No go. You cannot access this data source from Power Query.
Custom connector. “Built-in connector” and “custom connector” sound like opposites. Either you may need to fork out a bit of $$ to get a custom connector created, or give up.
Something else. Hmm…what are the other options?
I’d suggest starting with “something else.” When Power Query doesn’t ship with a connector for your source of interest, there are a number of other options to consider.
Let’s take a journey through the main other options for directly connecting to a source from Power Query. We’ll order these into “stages” based on an approximation of the level of effort involved. Then, we’ll expand our scope and touch on several possibilities that involve using external tools or languages to provide the needed data to Power Query.
You’ve built a custom connector—and it works great! But regardless of how good your query folding implementation is, likely there are times that a hand-crafted native query can beat it in performance and capability. So, in addition to supporting query folding, you’d like to give users the option of using native requests that they write with your connector.
In a nutshell, you’re hoping to enable something like:
let
Source = MyConnector.DataSourceFunction("some-host"),
Results = Value.NativeQuery(Source, "some native request goes here")
in
Results
Is this possible? From Power Query’s perspective, at the technical level: Yes—and it is easy to pull off.
Your Power Query contains more columns than you need. How do you get rid of the ones you don’t want? The mechanics of making extraneous columns go away is easy: in Query Editor, right click on a column and choose either Remove Columns or Remove Other Columns—but what differentiates these two options?
A Power Query mashup expression dies with an error. As the error propagates through your code, did you know that it sometimes collects a “journal” of the locations (e.g. line numbers) it passes through? This “expression stack,” as it’s called, can be used to help identify the troublemaking line of code.
An error’s expression stack is not automatically exposed in any user interface. Its hidden presence suggests that it may be a component supporting some past, present or planned UI functionality (perhaps it’s part of powering the “Go to Error” button?). Even though it is hidden, there may be cases where you find the location details it contains useful when debugging. Even if not, knowing about it is interesting Power Query trivia. 🙂
If a table view handler raises an error, Power Query’s default behavior is to suppress the error and instead perform the requested operation internally. In a nutshell, Power Query internally does whatever it was that the user requested, since the view was unable to do so.
But what if this isn’t the desired behavior—what if a view handler should stop an operation from taking place, so the user sees it dying with an error?
Table.Schema offers to expose a variety of details about a table’s columns. Your custom connector can leverage this functionality to give users easy access to column-specific details from the external data source about the tables they are fetching.
Say that external source allows users to create new columns and give them descriptions. Why not make these descriptions available from within Power Query by having them appear in Table.Schema‘s Description column? Perhaps the type system on the source is a bit different from Power Query’s. Table.Schema columns like NativeTypeName, NumericScale and NumericPrecision can be used to communicate relevant details to your users for reference purposes, enhancing their understanding of the data they’re pulling.
How?
The idea of exposing informative details about a source’s columns is great—but how do you provide this information in a way that Table.Schema will read it? The answer depends on which Table.Schema column you’re trying to populate.
While these techniques may primarily be of interest to custom connector developers, they’re valid to use from any M code—no connector required.
The table you fetch from a web API mysteriously contains an unexpected row with a null value in each column. You manually try the API using a tool like Postman or Insomnia and don’t find any all-null objects in the raw response. Where is this null table row coming from?
Zero rows (again!).
Previously, we dug into refreshes mysteriously dying with the complaint that “column ‘Column1’ of the table wasn’t found” even though no M code or data source schema changes had occurred. Upon investigation, we learned that an insufficiently in some fetch data M code results in it outputting zero columns when the web API returns no rows, which breaks later code that expects the presence of specific columns.
This time, zero rows is again the trigger condition, though it’s not zero rows altogether. Instead, it’s when a web API that returns paged responses returns a page containing no rows. Receiving back an empty page is a real-world possibility. For example, the last page of a response might contain zero rows because the rows that were to have been in it were deleted just moments ago, after the preceding page was fetched.
A common pattern for processing paged responses is to read the various pages into a list, then turn that list into a table, which is then expanded out into the appropriate rows and columns. However, the implementation of this flow sometimes leaves a corner case unaccounted for which leads to the all-null row being present. Unfortunately, such an oversight is present in Table.GenerateByPage (a function commonly used by custom connectors).
In the real world, errors are a part of life. If you access and read data from real, in-production systems, sooner or later you will almost certainly encounter errors. While you may be unable to escape their unfortunate reality, at least in the Power Query world, they’re rendered out in an easy-to-read format:
Easy to read, that is, if you are a human, reading just one error all by itself.
But what if you’re trying to analyze a collection of error messages? Imagine a set of errors like the above, but which are for a variety of different codes and problems (e.g. bad code ‘A235’, problem ‘must contain at least 2 letters’, bad code ’15WA’, problem ‘cannot start with a number’, etc.).
Let’s say you want to summarize these errors, reporting out the count of errors per problem, per bad code. Manually reading errors one at a time no longer cuts it. Instead, you could write code that parses each error message, extracting the text between the phrase bad code ‘ and the following quote character, and between problem ‘ and the following quote character. With the code and problem statement now separately captured, you can use their values to group by or otherwise compute the desired summaries.
Parsing log messages like this this involves coding work. Not only does it take effort on your part, but it is also tricky to get right. For example, the logic described above finds the end of each string it matches by looking for the next quote character. What if a bad code or problem description includes a quote character? The logic we’ve been considering won’t match the entire value. Say, the message starts with Bad code ‘ABC’DEF’. The above logic will miss the second portion of the code (only capturing ABC, not the full ABC’DEF) because it incorrectly assumes that a bad code will never contain a quote. You could address this by writing more robust parsing code, but that’s more work—and this is only one example of the corner cases you may need to handle to accurately parse a family of log messages.
On the other hand, maybe your interest is not analyzing log message parameters, but rather removing them altogether. For data privacy or security reasons, you want sanitized log messages, where parameter values have been stripped out and replaced with generic placeholders. This way, “clean” log messages can be aggregated or retained long-term without the complications that accompany storing PII or other confidential information that may have found its way into error message parameters. While this may be the opposite of our first scenario (extracting message parameters for analysis purposes), implementing it still requires a technical means to differentiate between the base log message pattern (or template) and the parameters that have been filled into it. If you’re implementing this yourself, you’re looking at some form of log message parsing.
In either case, if only there was a way to avoid the effort and complexity associated with writing log message parsing code….
Introducing M’s Structured Error Messages
Meet M’s new structured error message capabilities!
M’s error functionality has recently been expanded to offer a new way of defining error messages, splitting message definition between a template and a list of parameter values. These components are preserved with first class representation in the error after it is raised, enabling error handling code (and, potentially by extension, external logging mechanisms and log analytics tools) to separately work with these components without the need for custom text parsing. This style of error message is known as a structured error message and is key to making structured logging possible.
The error seems to escape catching. When the expression is evaluated, Query Editor displays the error. Try loading the query’s output into Microsoft Power BI or Excel and the operation dies with an error. Clearly, there’s an error—but if you wrap the expression with a try, the error isn’t caught! To the contrary, the record output by try reports HasError = false, even though if you access that record’s Value field, Query Editor again shows the error.
What’s going on?! Have you discovered an uncatchable error? Is this a Power Query bug?